c++虚函数(一)
虚函数是C++中用于实现多态(polymorphism)的机制。核心理念就是通过基类访问派生类定义的函数。假设我们有下面的类层次:
class="tags" href="/tags/CLASS.html" title=class>class A
{
public:
virtual void foo() { cout << "A::foo() is called" << endl;}
};
class="tags" href="/tags/CLASS.html" title=class>class B: public A
{
public:
virtual void foo() { cout << "B::foo() is called" << endl;}
};
A * a = new B();
a->foo(); // 在这里c;a虽然是指向A的指针c;但是被调用的函数(foo)却是B的!
这个例子是虚函数的一个典型应用c;通过这个例子c;也许你就对虚函数有了一些概念。它虚就虚在所谓“推迟联编”或者“动态联编”上c;一个类函数的调用并不是在编译时刻被确定的c;而是在运行时刻被确定的。由于编写代码的时候并不能确定被调用的是基类的函数还是哪个派生类的函数c;所以被成为“虚”函数。
虚函数只能借助于指针或者引用来达到多态的效果c;如果是下面这样的代码c;则虽然是虚函数c;但它不是多态的:
class="tags" href="/tags/CLASS.html" title=class>class A
{
public:
virtual void foo();
};
class="tags" href="/tags/CLASS.html" title=class>class B: public A
{
virtual void foo();
};
void bar()
{
A a;
a.foo(); // A::foo()被调用
}
1.1 多态
在了解了虚函数的意思之后c;再考虑什么是多态就很容易了。仍然针对上面的类层次c;但是使用的方法变的复杂了一些:
void bar(A * a)
{
a->foo(); // 被调用的是A::foo() 还是B::foo()?
}
因为foo()是个虚函数c;所以在bar这个函数中c;只根据这段代码c;无从确定这里被调用的是A::foo()还是B::foo()c;但是可以肯定的说:如果a指向的是A类的实例c;则A::foo()被调用c;如果a指向的是B类的实例c;则B::foo()被调用。
这种同一代码可以产生不同效果的特点c;被称为“多态”。
1.2 多态有什么用?
多态这么神奇c;但是能用来做什么呢?这个命题我难以用一两句话概括c;一般的C++教程(或者其它面向对象语言的教程)都用一个画图的例子来展示多态的用途c;我就不再重复这个例子了c;如果你不知道这个例子c;随便找本书应该都有介绍。我试图从一个抽象的角度描述一下c;回头再结合那个画图的例子c;也许你就更容易理解。
在面向对象的编程中c;首先会针对数据进行抽象(确定基类)和继承(确定派生类)c;构成类层次。这个类层次的使用者在使用它们的时候c;如果仍然在需要基类的时候写针对基类的代码c;在需要派生类的时候写针对派生类的代码c;就等于类层次完全暴露在使用者面前。如果这个类层次有任何的改变(增加了新类)c;都需要使用者“知道”(针对新类写代码)。这样就增加了类层次与其使用者之间的耦合c;有人把这种情况列为程序中的“bad smell”之一。
多态可以使程序员脱离这种窘境。再回头看看1.1中的例子c;bar()作为A-B这个类层次的使用者c;它并不知道这个类层次中有多少个类c;每个类都叫什么c;但是一样可以很好的工作c;当有一个C类从A类派生出来后c;bar()也不需要“知道”(修改)。这完全归功于多态--class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器针对虚函数产生了可以在运行时刻确定被调用函数的代码。
1.3 如何“动态联编”
class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器是如何针对虚函数产生可以再运行时刻确定被调用函数的代码呢?也就是说c;虚函数实际上是如何被class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器处理的呢?Lippman在深度探索C++对象模型[1]中的不同章节讲到了几种方式c;这里把“标准的”方式简单介绍一下。
我所说的“标准”方式c;也就是所谓的“VTABLE”机制。class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器发现一个类中有被声明为virtual的函数c;就会为其搞一个虚函数表c;也就是VTABLE。VTABLE实际上是一个函数指针的数组c;每个虚函数占用这个数组的一个slot。一个类只有一个VTABLEc;不管它有多少个实例。派生类有自己的VTABLEc;但是派生类的VTABLE与基类的VTABLE有相同的函数排列顺序c;同名的虚函数被放在两个数组的相同位置上。在创建类实例的时候c;class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器还会在每个实例的内存布局中增加一个vptr字段c;该字段指向本类的VTABLE。通过这些手段c;class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器在看到一个虚函数调用的时候c;就会将这个调用改写c;针对1.1中的例子:
void bar(A * a)
{
a->foo();
}
会被改写为:
void bar(A * a)
{
(a->vptr[1])();
}
因为派生类和基类的foo()函数具有相同的VTABLE索引c;而他们的vptr又指向不同的VTABLEc;因此通过这样的方法可以在运行时刻决定调用哪个foo()函数。
虽然实际情况远非这么简单c;但是基本原理大致如此。
1.4 overload和override
虚函数总是在派生类中被改写c;这种改写被称为“override”。我经常混淆“overload”和“override”这两个单词。但是随着各类C++的书越来越多c;后来的程序员也许不会再犯我犯过的错误了。但是我打算澄清一下:
override是指派生类重写基类的虚函数c;就象我们前面B类中重写了A类中的foo()函数。重写的函数必须有一致的参数表和返回值(C++标准允许返回值不同的情况c;这个我会在“语法”部分简单介绍c;但是很少class="tags" href="/tags/CLASS.html" title=class>class="tags" href="/tags/BianYiQi.html" title=编译器>编译器支持这个feature)。这个单词好象一直没有什么合适的中文词汇来对应c;有人译为“覆盖”c;还贴切一些。
overload约定成俗的被翻译为“重载”。是指编写一个与已有函数同名但是参数表不同的函数。例如一个函数即可以接受整型数作为参数c;也可以接受浮点数作为参数。
本文来自CSDN博客c;转载请标明出处:http://blog.csdn.net/dchcuckoo/archive/2005/10/14/503998.aspx
相关文章

TimeDistributed()层应用于自定义层出现NotImplementedError
显示acc和lose时出现:KeyError: ‘sparse_categorical_accuracy‘
TensorFlow2.X绘制常见图像(如AUC,acc,recall等等)
tensorflow2.x训练模型出现nan
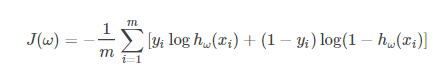
损失函数softmax_cross_entropy、binary_cross_entropy、sigmoid_cross_entropy之间的区别与联系
- 常州哪些网站公司做的好处/人民网今日头条
- 公司想制作网站/怎样制作免费网页
- 网站开发 语言net/上海百度推广官网
- 工商网站如何下载建设银行u盾证书/网页模板怎么用
- wordpress 微网站模板/推广关键词优化
- 泉州城乡建设网站/专业提升关键词排名工具
- 国产化浪潮下,高科技企业如何选择合适的国产ftp软件方案?
- 【LeetCode】【算法】240. 搜索二维矩阵II
- test 是 JavaScript 中正则表达式对象 (RegExp) 的一种方法,用于测试一个字符串是否匹配某个正则表达式
- C#中接口与类的区别(转摘
- Day04 - Array Cardio 指南一
- python GUI开发 工具选择